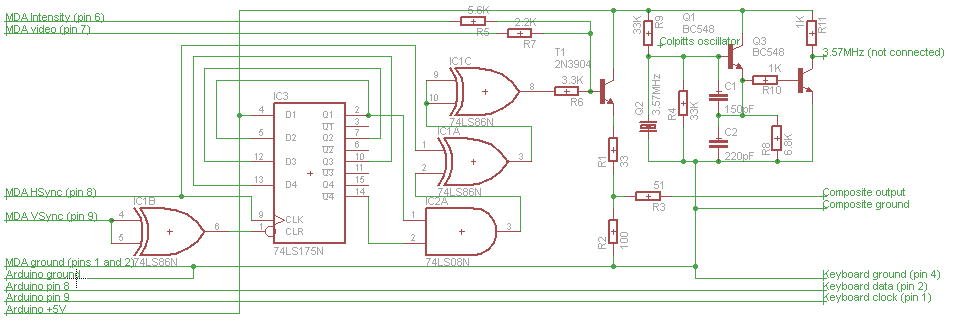
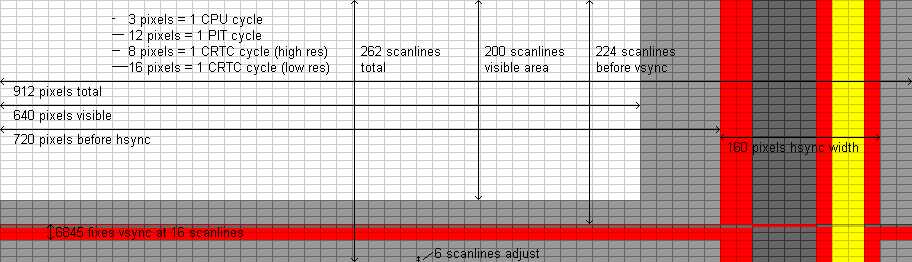
This was a question which puzzled me when I first found out about it, but now that I understand all the history behind it, it makes perfect sense.
The IBM PC (5150) was originally designed output to an NTSC television in mind - hence the 4.77MHz clock speed (4/3 the NTSC color carrier frequency - allowing the video output and CPU clock to share a crystal). It was thought that home users would generally hook their PCs up the TV rather than having a separate, expensive, monitor. Another major limiting factor in the design of the CGA was the price of video memory - the 16Kb on the card would have been fairly expensive at the time (it was as much as the amount of main memory in the entry level PC). TV resolution is 912x262 at CGA 2-colour pixel sizes in non-interlaced mode, but TVs (especially CRTs) don't show all of the image - some of those scanlines and pixels are devoted to sync signals and others are cropped out because they would be distorted due to the difficulties of approximating high frequency sawtooth waves with high-voltage analog circuitry. So 320x200 4-colour and 640x200 2-colour packed pixel modes were chosen because they were a good fit for both 16Kb of memory and TV resolutions.
That system did work quite well for many home users - lots of CGA games have 16-colour composite output modes. But it wasn't so good for business users. These users tended not to care so much about colour but did care about having lots of columns of text - 80 was a common standard for interfacing with mainframes and for printed documents. But 80-column text on a TV or composite monitor is almost completely illegible, especially for colour images - alternating columns of black and white pixels in a mode with 320 pixels horizontally gets turned into a solid colour by NTSC. So for business users, IBM developed a completely separate video standard - MDA. This was a much simpler monochrome text device with 4Kb of memory - enough for 80 columns by 25 rows of text. To display high quality text, IBM decided on a completely different video standard - 370 scanlines (350 active) by 882 pixels (720 active) at 50Hz, yielding a 9x14 pixel grid for high-fidelity (for the time) character rendering. In terms of timings, the character clock is similar (but not identical) to that of the CGA 80-column text mode (presumably 16.257MHz crystals were the closest they could source to a design target of 16.108MHz). To further emphasize the business target of the MDA card, the printer port was built into the same card (a printer would have been de-rigour for a business user but a rare luxury for a home user). Business users would also usually have purchased an IBM 5151 (green-screen monitor designed for use with MDA) and IBM 5152 (printer).
CGA also had a digital TTL output for displaying high quality 16-colour 80-column text (at a lower resolution than MDA) on specially designed monitors such as the IBM 5153 - this seems to have been much more popular than the composite output option over the lifetime of these machines. The two cards used different memory and IO addresses, so could coexist in the same machine - real power users would have had two monitors, one for CGA and one for MDA (and maybe even a composite monitor as well for games which preferred that mode). The 9-pin digital connectors for CGA and MDA were physically identical and used the same pins for ground (1 and 2), secondary intensity (7), horizontal sync (8) and vertical sync (9) but CGA used 3, 4 and 5 for primary red, primary green and primary blue respectively whereas MDA used pin 7 for its primary video signal. MDA also used a negative-going pulse to indicate vertical sync while the CGA's vertical sync pulse is positive-going.
So for a while these two incompatible standards coexisted. The next major graphics standard IBM designed was the EGA, and one of the major design goals for this card was to be an upgrade path for both home and business users that did not require them to buy a new monitor - i.e. it should be compatible with both CGA and MDA monitors. This was accomplished by putting a 16.257MHz crystal on the card and having a register bit to select whether that or the 14.318MHz one would be used for the pixel clock (and by having the on-board video BIOS ROM program the CRTC appropriately). By 1984, it was not out of the question to put 128Kb of RAM on a video card, though a cheaper 64Kb option was also available. 64Kb was enough to allow the highest CGA resolution (640x200) with each pixel being able to display any of the CGA's 16 colours - these would have been the best possible images that CGA monitors such as the IBM 5153 could display. It was also enough for 4 colours at the higher 640x350 resolution - allowing graphics on MDA monitors. With 128Kb you got the best of both worlds - 16 colours (from a palette of 64) at 640x350.
IBM made a special monitor (the 5154) for use with the EGA. This monitor could display both 200-line and 350-line images (deciding which to use by examining the vertical sync pulse polarity), and allowed users would be able to take advantage of all 64 colours available in 350-line modes. The video connector was again physically the same and pins 1, 3, 4, 5, 8 and 9 had identical functions, but pins 2, 6 and 7 were repurposed as secondary red, green and blue signals respectively, allowing all 64 possible colours. But they wanted this monitor to be compatible with CGA cards as well, which meant that in 200 line mode it needed to interpret pins 3-6 as RGBI instead of RGBg and ignore pins 2 and 7. So even with a 5154, the EGA needed to generate a 4-bit signal when connected to a CGA monitor, disabling pins 2 and 7.
I guess the designers thought that sacrificing 48 of EGA's colours in 200-line modes was a small price to pay for making the EGA monitor compatible with CGA cards. Presumably they thought that if you had an EGA card and an EGA monitor you would be using 350-line mode anyway, or be running legacy CGA software which wouldn't miss those extra colours.
One thing I haven't mentioned here is the PCjr graphics. For the purposes of the discussion above it's essentially the same as CGA (it has the same outputs) but it's more flexible and slower due to the use of system RAM as video RAM, as many 8-bit microcomputers did in the 80s.