I used to think that the truth was just that - The Truth, singular. That there was just one "Platonic" set of true mathematical facts. I no longer subscribe to this point of view - what's true depends on who you ask.
First there are some basic truths that we have to agree on to have a discussion about anything, like "if A is true, and if A implies B, then B is also true". If we don't accept these basic logical principles as true the consequences are simply that we can't deduce anything, or that we have to accept that everything is true, or that nothing is true. We accept these truths because if we didn't what we get is a rather limited and boring set of mathematics, useless for doing anything interesting (like modelling the real world) with. Those who would deny them can't be disproven, but they can't be reasoned with either. So these truths just have to be admitted as axioms.
Next there are empirical truths like "the sky is blue" and "2+2=4". These can be thought of as facts about the universe we live in. We know they are true because we can see that they are. One could in principle do mathematics without such facts (just using pure logic) but most mathematicians generally accept these truths as well as it makes mathematics more interesting (and definitely more useful).
Sometimes mathematicians envisage mathematical objects which cannot exist in our universe - objects which are infinite in some sense (not necessarily infinitely big - a perfect sphere is infinitely smooth, for example, and the real number line contains infinitely many points). Infinity is a very slippery thing to deal with precisely because infinities are never directly observed in the universe. How can we say anything about infinity then? Well, mathematicians have developed techniques like "epsilon delta" (for every delta you can name, no matter how small, I can name an epsilon with such and such a property). These arguments break down in physics (nothing can be smaller than the Planck length or the concentration of energy required to confine it in that interval would cause a black hole) so they are purely mathematical in nature. Nevertheless they form a consistent and beautiful theory, and they do turn out to be useful for approximating physics, so we accept them.
But when infinities start to get involved, things get very weird - you start to find that there are multiple different versions of mathematics (multiple different sets of "true facts") which are consistent with themselves, consistent with our universe and interesting. Two of these are accepting and denying the "Axiom of Choice" (AC). If we accept the AC it allows us to prove things about infinities without actually constructing or defining them. This has some very weird results (like being able to disassemble a sphere into 5 pieces, move and rotate them and end up with 2 identical spheres of the same size as the original with no gaps). But denying the AC also gives you some weird results (every set can be put into order). Each are just as "true" but give different sets of mathematics. Currently mathematics including the AC is more popular as it seems to provide greater richness of intellectual territory.
As mathematics develops, it seems likely that more of these "interesting" axioms will be discovered (some of which might already have been assumed in some proofs) and that mathematics will fracture into increasng numbers of "branches" depending on which axioms one chooses to accept and which to deny. In fact, Gödel's Incompleteness Theorem says that for any axiomatic system of mathematics there will be "obviously true" statements that can't be proved from these axioms, in other words that the "bulk of mathematics" (though not necessarily the bulk of interesting mathematics) is found at the leaves of this metamathematical tree.
There are other branches of mathematics whose "truth value" is currently unknown to human mathematicians. For example, many theorems have been proven under the assumption that the Riemann hypothesis is true. We think it probably is but nobody has been able to prove it yet. The volume of work which assumes it makes it one of the most important unsolved problems.
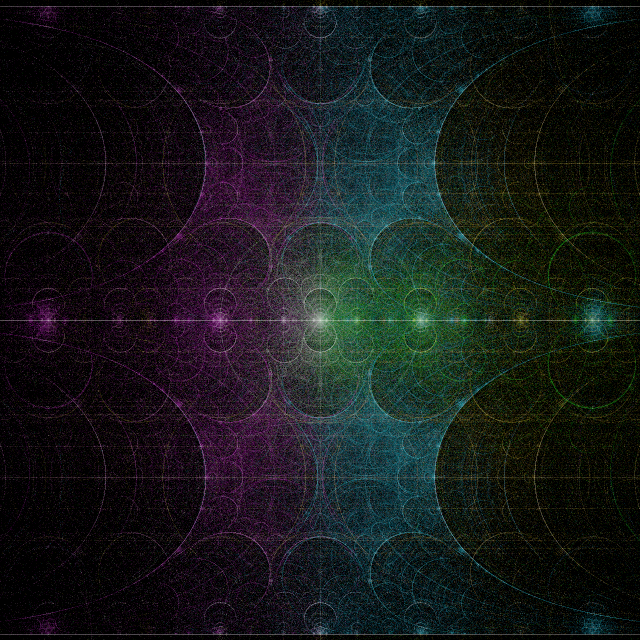


") = the nth iterate of the Mandelbrot equation (
= the nth iterate of the Mandelbrot equation ( ).
).") = distance between x+iy and the closest point in the Mandelbrot set. Phase could also encode direction.
= distance between x+iy and the closest point in the Mandelbrot set. Phase could also encode direction.") = the potential field around an electrically charged Mandelbrot set.
= the potential field around an electrically charged Mandelbrot set.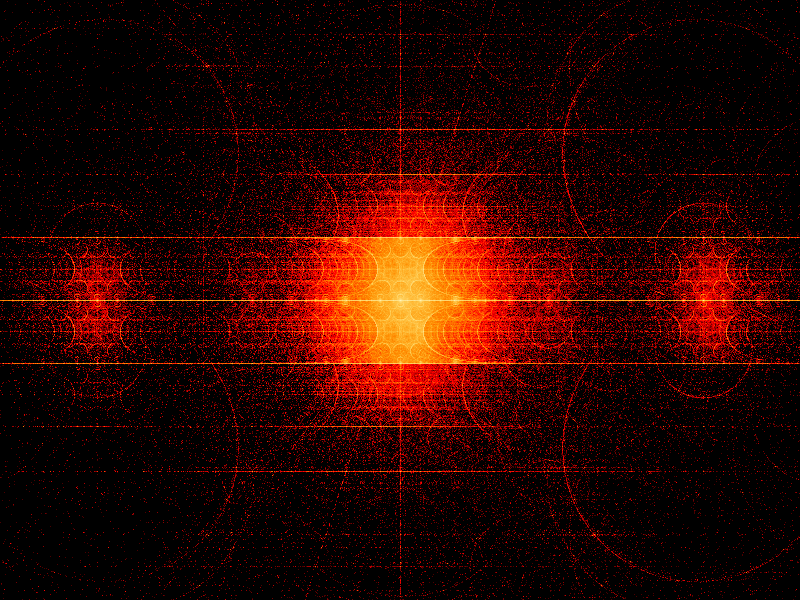
{kind=link}